
RAP: Reasoning with Language Model is Planning with World Model
https://arxiv.org/pdf/2305.14992
This is a wild card entry in the agents series. I started reading the LATS paper but it kept referring to this paper, especially w.r.t. “world models”. Then I thought I would just skim over the Reasoning via Planning (RAP) paper but ended up spending all Sunday afternoon on it.
I will be approaching this paper from our existing agent-planning knowledge base. But there is so much overlap with Reinforcement Learning that you will end up asking isn’t it Q-Learning? It’s not.
This is a pretty dense read. I don’t expect anyone to understand the whole thing in one pass. You will need to re-read a few times and think through this. FYI, this would be easy if you are familiar with RL though.
Read this one carefully as LATS paper would be combination of all the ideas discussed in last few papers and this one.
Tree-of-Thoughts (ToT) and RAP are really close in terms of their approach or mental model. Because both of them propose the following three items:
A non-linear search of the solution over LM output
Expansion of the existing nodes
And a criterion to prune (or prioritize) the tree for an efficient (time & cost) search
Not only that but if you use the Monte Carlo Tree Search in Tree of Thoughts you get RAP (almost).
The difference between ToT and RAP comes from how they treat the model output. ToT treats it as “Thought” and RAP as “Explicit State”. Thought is at a higher abstraction because it combines state of the problem being solved and the corresponding action that it may take next. I think RAP makes it more explicit by breaking thought into “State” which represents nodes and “Actions” which represents “edges” that lead to a new state.
ToT or RAP in my opinion should be considered just different ways to think about the same problem. They aren’t competing but they are complementing each other.
Problem Statement
The problem statement is the same as ToT. The simple left-to-right reasoning doesn’t work well enough. And LLMs tend to compound the errors in previous thoughts in its subsequent thoughts.
The way humans think is if I do X, how would the world around me react to it? Even as humans, we don’t have all the knowledge about the problems or its environment we are trying to solve. We approximate it. That is we create models of the world. For example, if I ask you to move a couch, based on how the couch looks, you have estimated some weight or at least some notion of light and heavy. You don’t act, you think first about how much force you should apply to move it and course correct yourself if you are wrong.
LLMs have the knowledge of the world but they don’t know how to use it by default. CoT doesn’t help with that either because if they are wrong, you can’t course correct. RAP is trying to instill this think-act-observe-backtrack into LLM problem solving via agent and world model distinction.
Proposed Solution
RAP creates two roles for LLM, same model just used with different prompts. In one prompt we ask to produce action and in other we ask to predict the next state.
Agent - Given the state of the world and the goal, produce the next action.
World Model - When an action produced by the agent is applied, what is the next state.
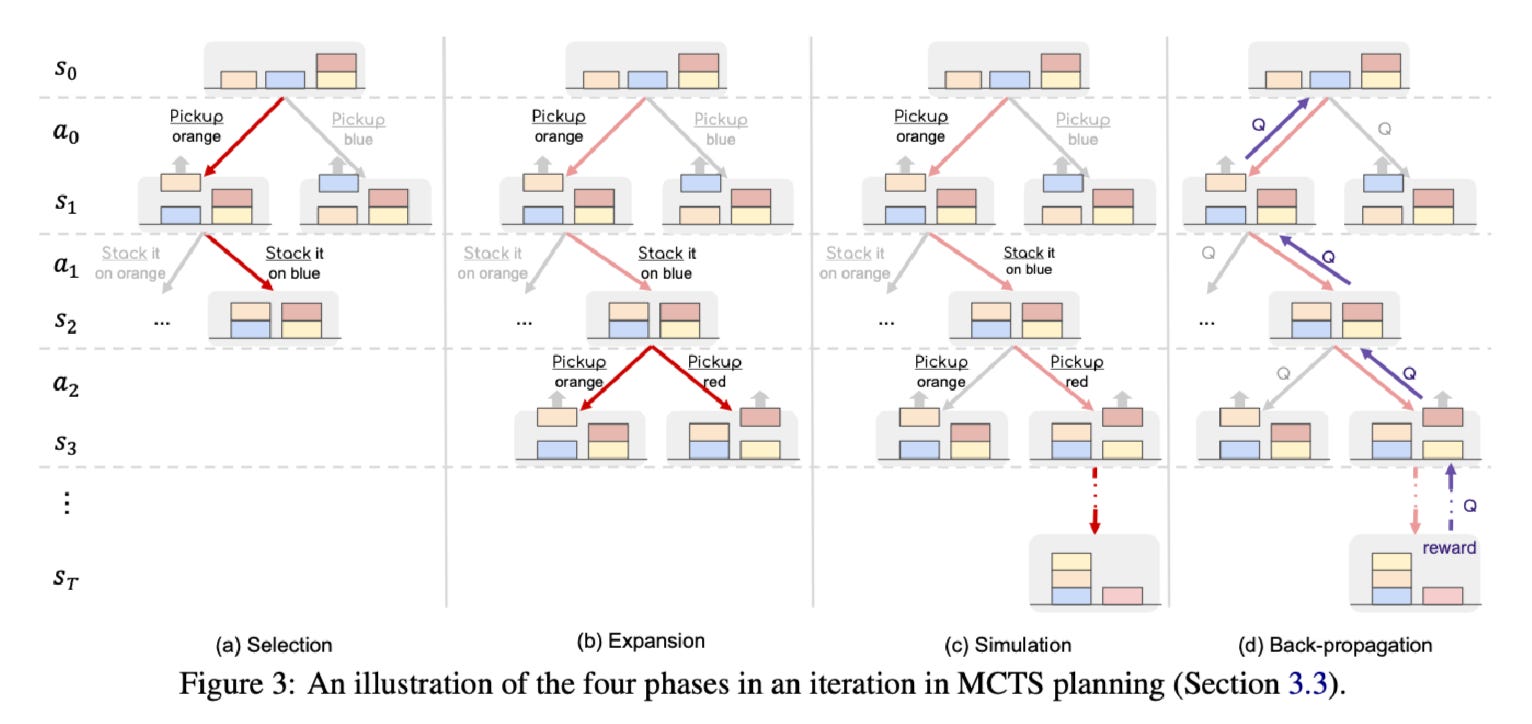
And the loop continues till we reach a terminal state. When we talk about the state and action, it is still plain English language describing the state and action in words. Take a look at the blocks example from the paper. And it is worth looking at the appendix for the actual prompts to solidify the understanding.

Now, if you just do the vanilla loop between the agent and the world model, we are doing left-to-right thinking and are prone to compounding errors similar to CoT. So, let’s add search over action space, i.e., given a state tell me the most optimal action I should take. The key word here is “optimal” - given a set of actions - how would I know which one is the most optimal? To quantify the “optimality” of this action we introduce something called “reward”. Let’s say you are using the LLMs to solve the maze navigation problem then reward could be -(steps to exit). The reason we use “-” (negative) sign is because we want the shortest path.
So, we have our agent which generates actions for a given state, then there is a world model which produces the next state if the action is applied. And once we reach the terminal state we get our reward for this particular trace of (state, action, state, action, …). But we don’t know if this is the path with the highest reward, this is just one of the possible paths. Because the agent samples (randomly generates) a bunch of actions and we select one (for now - randomly) and then just keep doing that till we reach a terminal state. There could be other paths that are more rewarding than this one that we haven’t explored yet. So, we backtrack and start again to look for a better path. We keep doing that till our budget (cost & time) allows.
One might say, if the reward is between [0, 1] then we do know that the maximum reward is 1 and if we reached there we should stop. Technically, you could. But still maximum reward doesn’t necessarily translate into best path or reasoning to get there. So, you still might want to keep exploring.
During each exploration above, we learn something about the current states in that path. That is how good or bad are these states (w.r.t. obtaining that reward) when a certain action is taken. And to capture and re-use that learning we store a number called q-value (action-value) for each state. The computation of reward and the q-value depends on the problem you are trying to solve. But once you have this q-value you can decide which action to explore out of a bunch that are generated from each state (this is a fix for the previous para where we said it was random).
Now, given the explanation above, I want you to see if you can understand the algorithm now from the paper by yourself. Here is an excellent video to learn more about the Monte Carlo Tree Search.

Note, above we discussed a simplified version of the rewards where you only get it at terminal node. But in RAP also computes intermediate rewards that guide the search. Focus on line number, 8, 13, and 17.
Observed Results
They tested RAP on three tasks: plan generation (Blocksworld), math reasoning (GSM8K), and logical inference (PrOntoQA). RAP consistently outperformed CoT and least-to-most prompting with self-consistency across all three.
The headline number is RAP on LLaMA-33B beating CoT on GPT-4 by 33% relative improvement in plan generation. A smaller model with a better reasoning strategy outperformed a much larger model doing left-to-right thinking.
It is a test-time-compute technique so it has that quality vs compute (cost) trade-off. The biggest assumption here is that the LLM would be able to represent the world model correctly enough to predict the next state. And this is one of the limitation that LATS tries to fix.
Thanks!